Background
Apache Airflow is an open-source platform which is used for orchestrating and automating workflows and data pipelines. It helps data professionals to programmatically author, schedule, monitor and manage workflows. A package which is perfect for tasks such as extracting, transforming and loading data into dashboards.
In this example we will be using a transnational retail dataset from a UK-based e-commerce site. The data will be extracted from a csv file and loaded into a google cloud storage, will be passed through several data quality checks, shaped with DBT and finally loaded into a dashboard using Metabase.
Note: This will not be a tutorial but rather a very quick summary of the process due to the project’s very complex nature. If you have any questions, feel free to contact me!
Highlights
🌟 Introduction and project overview
📊 Ingesting data from a CSV file into Google Cloud Storage
✅ Running data quality checks with SODA
🔄 Shaping the raw data and modeling with DBT and Airflow
🚀 Integrating DBT with Airflow using Cosmos
✅ Running data quality checks on transformed data
📈 Running DBT models for analytics
✅ Final data quality checks
📊 Building a dashboard with Metabase
Dataset
| Column | Description |
|---|---|
| InvoiceNo | Unique invoice number assigned to each transaction. If it starts with ‘c’, it indicates a cancellation. |
| StockCode | Unique code assigned to each product. |
| Description | Name of the product. |
| Quantity | Number of items purchased in each transaction. |
| InvoiceDate | Date and time of each transaction. |
| UnitPrice | Price per unit of the product. |
| CustomerID | Unique customer number assigned to each customer. |
| Country | Name of the country where each customer resides. |
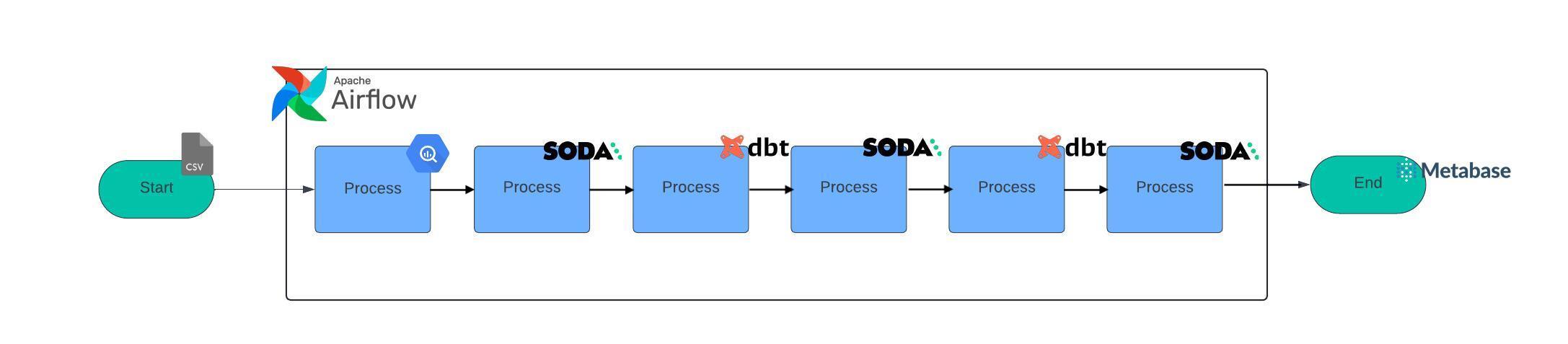
Data Pipeline Diagram
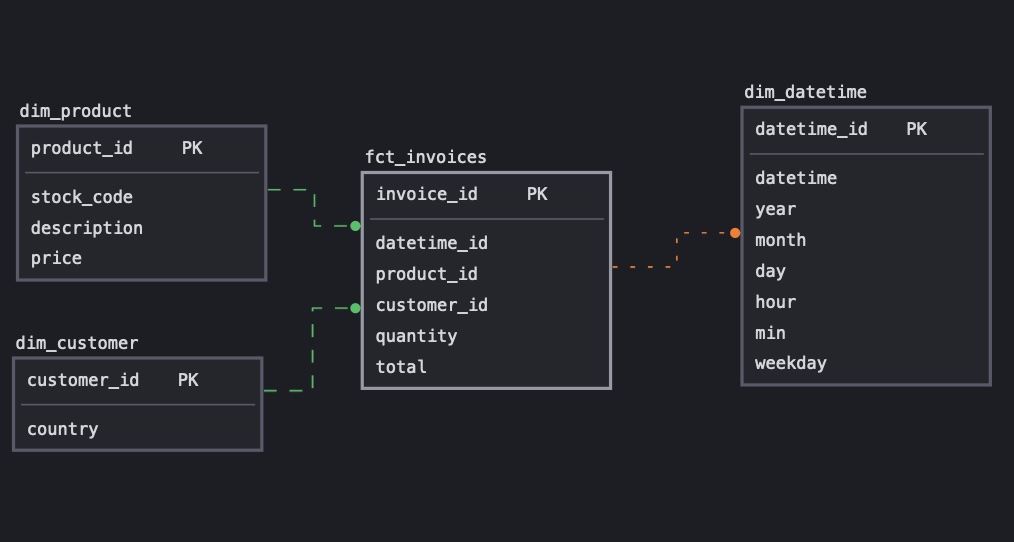
Data Model
Prerequisites
- Docker
- Astro CLI
- Soda
- Google Cloud Storage Account
# Import all necessary Libraries
from airflow.decorators import dag, task
from datetime import datetime
from airflow.providers.google.cloud.transfers.local_to_gcs import LocalFilesystemToGCSOperator
from airflow.providers.google.cloud.operators.bigquery import BigQueryCreateEmptyDatasetOperator
from astro import sql as aql
from astro.files import File
from airflow.models.baseoperator import chain
from astro.sql.table import Table, Metadata
from astro.constants import FileType
from include.dbt.cosmos_config import DBT_PROJECT_CONFIG, DBT_CONFIG
from cosmos.airflow.task_group import DbtTaskGroup
from cosmos.constants import LoadMode
from cosmos.config import ProjectConfig, RenderConfig
The core concept of Airflow is using DAGs (Directed Acyclic Graph), which in essence is a collection of tasks organized with dependencies and built with detailed relationships on how they should run. It’s a perfect tool to automate, organize, and monitor complex data pipelines.
The first step in the data pipeline is to download the CSV from the Kaggle site and store it in a Google Cloud Storage (GCS) bucket. After storing it in a bucket, a service account is created with a unique name. The DAG can only access the GCS account by providing it with the service_account.json file.
Declaring the DAG and Uploading CSV to a Google Cloud Storage Bucket
There are three ways to declare a DAG, my preference is by using the @dag decorator. In this case the DAG is named retail() and has one task, to run upload_csv_to_gcs which uses the *LocalFilesystemToGCSOperator() operator. An Operator is simply a predefined task or a python function. Most operators have the option to declare several parameters for customization, the same as regular python functions! It is necessary to call retail() line at the end, otherwise it will not run the DAG.
from airflow.decorators import dag, task
from datetime import datetime
from airflow.providers.google.cloud.transfers.local_to_gcs import LocalFilesystemToGCSOperator
@dag(
start_date = datetime(2024,1,1),
schedule=None,
catchup=False,
tags=['retail'],
)
def retail():
upload_csv_to_gcs = LocalFilesystemToGCSOperator(
task_id='upload_csv_to_gcs',
src = '/usr/local/airflow/include/dataset/Online_Retail.csv',
dst = 'raw/online_retail.csv',
bucket='larrysaavedra_online_retail',
gcp_conn_id = 'gcp',
mime_type='text/csv',
)
retail()
At any point after adding a task to the DAG, one should be able to see the DAG visually represented within the Airflow UI. Another benefit of using Airflow!
Creating the Schema and Loading the CSV Data into BigQuery
Next an empty Dataset (schema) named retail is created in BigQuery in order to upload the data from the bucket named larrysaavedra_online_retail into BigQuery. Again the task create_retail_dataset uses the operator BigQueryCreateEmptyDatasetOperator to do that.
from airflow.providers.google.cloud.operators.bigquery import BigQueryCreateEmptyDatasetOperator
create_retail_dataset = BigQueryCreateEmptyDatasetOperator(
task_id='create_retail_dataset',
dataset_id='retail',
gcp_conn_id='gcp',
)
At this point of time we only have a schema created but no tables. The next task gcs_to_raw below does just that, it loads the CSV file into a table called raw_invoices.
from astro import sql as aql
from astro.files import File
from astro.sql.table import Table, Metadata
from astro.constants import FileType
gcs_to_raw = aql.load_file(
task_id='gcs_to_raw',
input_file=File(
'gs://larrysaavedra_online_retail/raw/online_retail.csv',
conn_id='gcp',
filetype=FileType.CSV,
),
output_table=Table(
name='raw_invoices',
conn_id='gcp',
metadata=Metadata(schema='retail')
),
use_native_support=False,
)
The data is officially now uploaded into the warehouse!
Integrating the Soda CLI with Apache Airflow
Soda is a data quality testing tool that can be integrated with several services, in this example we will be using it throughout the data pipeline right after transforming the data. Here are a couple qualities that Soda can test for:
- Are there any missing values?
- Are there any unexpected duplicate values?
- Did something go wrong during the transformation of the data?
- Are all data values valid (correct data type)?
- How fresh is the data?
- Any inconsistent values disrupting anything downstream?
If, after a scan, Soda detects unexpected, invalid, or missing data, it will return a scan result that will help the user investigate and debug for quality issues.
There are a couple things that need to be done before Soda can be used with Airflow. First, one must make sure to have the Soda Core package under the requirements.txt file. Second, create a configuration.yml file which is used to provide details for Soda to connect with the data source (in this case BigQuery). Third, create a Soda account and create an API key which is then copied into the configuration.yml file.
Creating the First Soda Scan Test
We can finally focus on creating the first scan test for the raw_invoices table. Below is the yml file that will be used by Soda. In this example, it will check that there are no missing columns, and that each respective column has the correct data type. For example, InvoiceNo is a column that should be in the table and have only the string data type.
# Stored under include/soda/checks/sources/raw_invoices.yml
checks for raw_invoices:
- schema:
fail:
when required column missing: [InvoiceNo, StockCode, Quantity, InvoiceDate, UnitPrice, CustomerID, Country]
when wrong column type:
InvoiceNo: string
StockCode: string
Quantity: integer
InvoiceDate: string
UnitPrice: float64
CustomerID: float64
Country: string
This will only be one of a few yml scan files we will create, therefore it’s to our benefit to create an external function and a virtual environment for Soda to run the scan files when needed throughout the pipeline.
Below is the function that will run the scan files, all we have to do is replace the checks_subpath parameter with the folder path where the scan yml file is located and give it a custom name under the parameter scan_name.
# include/soda/check_function.py
def check(scan_name, checks_subpath=None, data_source='retail', project_root='include'):
from soda.scan import Scan
print('Running Soda Scan ...')
config_file = f'{project_root}/soda/configuration.yml'
checks_path = f'{project_root}/soda/checks'
if checks_subpath:
checks_path += f'/{checks_subpath}'
scan = Scan()
scan.set_verbose()
scan.add_configuration_yaml_file(config_file)
scan.set_data_source_name(data_source)
scan.add_sodacl_yaml_files(checks_path)
scan.set_scan_definition_name(scan_name)
result = scan.execute()
print(scan.get_logs_text())
if result != 0:
raise ValueError('Soda Scan failed')
return result
After creating a virtual environment for Soda, we can officially add a new task to our DAG using ExternalPython which will use the virtual environment with all the Soda dependencies pre-installed. This makes the script run much faster, rather than using VirtualPython where dependencies have to be installed during each run.
We call this task check_load all it does is run the raw_invoices scan which is stored under a sub folder called sources. In order to run this scan, we simply have to call the check_load() function as declared below.
@task.external_python(python='/usr/local/airflow/soda_venv/bin/python')
def check_load(scan_name='check_load', checks_subpath='sources'):
# Recall this is the function check_function we created above!
from include.soda.checks.sources.check_function import check
return check(scan_name, checks_subpath)
The first data quality check is in place, and we can finally move to our first transformation of our raw data!
Conducting the First Data Transformation with DBT and Cosmos
DBT (Data Build Tool) is an open-source tool that streamlines the process of transforming and managing data, a pretty neat tool for modern data teams. Cosmos in the other hand is probably one the best ways to integrate dbt and airflow. Using Cosmos helps you visualize what is occurring inside dbt when it’s integrated with airflow. Additionally you can transform these DBT projects into Tasks Groups making it easier to manage code and debug.
Once again before anything can be done with DBT, Cosmos needs to be properly installed through the requirements.txt file, a virtual environment created within the Dockerfile, linked up with the airflow environment, and finally create a new table called retail.country within BigQuery using the following query. At this point two tables should exist in BigQuery, raw_invoices and country.
Creating the DBT models
First we need to tell DBT what data it needs to look for to transform.
# The following information should be in a yml file named sources.yml under the following path include/dbt/models/
version: 2
sources:
- name: retail
database: airtube-390719 # Put the project id!
tables:
- name: raw_invoices
- name: country
The following code snippets are the actual models that DBT will be making during the flow. Models are simply the representation of a table or a view of a data model. DBT accepts SQL statements to conduct transformations and create tables.
Recall from the ERD at the beginning of this post that we should have 4 tables. All these models should be under the path include/dbt/models/transform in the airflow project.
-- dim_customer.sql
-- Create the dimension table
WITH customer_cte AS (
SELECT DISTINCT
{{ dbt_utils.generate_surrogate_key(['CustomerID', 'Country']) }} as customer_id,
Country AS country
FROM {{ source('retail', 'raw_invoices') }}
WHERE CustomerID IS NOT NULL
)
SELECT
t.*,
cm.iso
FROM customer_cte t
LEFT JOIN {{ source('retail', 'country') }} cm ON t.country = cm.nicename
-- dim_datetime.sql
-- Create a CTE to extract date and time components
WITH datetime_cte AS (
SELECT DISTINCT
InvoiceDate AS datetime_id,
CASE
WHEN LENGTH(InvoiceDate) = 16 THEN
-- Date format: "DD/MM/YYYY HH:MM"
PARSE_DATETIME('%m/%d/%Y %H:%M', InvoiceDate)
WHEN LENGTH(InvoiceDate) <= 14 THEN
-- Date format: "MM/DD/YY HH:MM"
PARSE_DATETIME('%m/%d/%y %H:%M', InvoiceDate)
ELSE
NULL
END AS date_part,
FROM {{ source('retail', 'raw_invoices') }}
WHERE InvoiceDate IS NOT NULL
)
SELECT
datetime_id,
date_part as datetime,
EXTRACT(YEAR FROM date_part) AS year,
EXTRACT(MONTH FROM date_part) AS month,
EXTRACT(DAY FROM date_part) AS day,
EXTRACT(HOUR FROM date_part) AS hour,
EXTRACT(MINUTE FROM date_part) AS minute,
EXTRACT(DAYOFWEEK FROM date_part) AS weekday
FROM datetime_cte
-- dim_product.sql
-- StockCode isn't unique, a product with the same id can have different and prices
-- Create the dimension table
SELECT DISTINCT
{{ dbt_utils.generate_surrogate_key(['StockCode', 'Description', 'UnitPrice']) }} as product_id,
StockCode AS stock_code,
Description AS description,
UnitPrice AS price
FROM {{ source('retail', 'raw_invoices') }}
WHERE StockCode IS NOT NULL
AND UnitPrice > 0
-- fct_invoices.sql
-- Create the fact table by joining the relevant keys from dimension table
WITH fct_invoices_cte AS (
SELECT
InvoiceNo AS invoice_id,
InvoiceDate AS datetime_id,
{{ dbt_utils.generate_surrogate_key(['StockCode', 'Description', 'UnitPrice']) }} as product_id,
{{ dbt_utils.generate_surrogate_key(['CustomerID', 'Country']) }} as customer_id,
Quantity AS quantity,
Quantity * UnitPrice AS total
FROM {{ source('retail', 'raw_invoices') }}
WHERE Quantity > 0
)
SELECT
invoice_id,
dt.datetime_id,
dp.product_id,
dc.customer_id,
quantity,
total
FROM fct_invoices_cte fi
INNER JOIN {{ ref('dim_datetime') }} dt ON fi.datetime_id = dt.datetime_id
INNER JOIN {{ ref('dim_product') }} dp ON fi.product_id = dp.product_id
INNER JOIN {{ ref('dim_customer') }} dc ON fi.customer_id = dc.customer_id
Now that we have have given DBT the exact transformations that need to be done, we can finally add it as a task within Airflow. The task will additionally need a DBT_CONFIG file in order for it to run properly.
from include.dbt.cosmos_config import DBT_PROJECT_CONFIG, DBT_CONFIG
from cosmos.airflow.task_group import DbtTaskGroup
from cosmos.constants import LoadMode
from cosmos.config import ProjectConfig, RenderConfig
transform = DbtTaskGroup(
group_id='transform',
project_config=DBT_PROJECT_CONFIG,
profile_config=DBT_CONFIG,
render_config=RenderConfig(
load_method=LoadMode.DBT_LS,
select=['path:models/transform']
)
)
# include/dbt/cosmos_config.py
from cosmos.config import ProfileConfig, ProjectConfig
from pathlib import Path
DBT_CONFIG = ProfileConfig(
profile_name='retail',
target_name='dev',
profiles_yml_filepath=Path('/usr/local/airflow/include/dbt/profiles.yml')
)
DBT_PROJECT_CONFIG = ProjectConfig(
dbt_project_path='/usr/local/airflow/include/dbt/',
)
The TaskGroup transform should now appear within the Airflow UI, and is now ready to be called when necessary!
Running Data Quality Checks on Transformed Data
Now at this point, one should be getting the gist of the process. The next step is to once again run some data quality checks using Soda.
We can create all the following yml files below under the following path: include/soda/checks/transform
# dim_customer.yml
checks for dim_customer:
- schema:
fail:
when required column missing:
[customer_id, country]
when wrong column type:
customer_id: string
country: string
- duplicate_count(customer_id) = 0:
name: All customers are unique
- missing_count(customer_id) = 0:
name: All customers have a key
# dim_datetime.yml
checks for dim_datetime:
# Check fails when product_key or english_product_name is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing: [datetime_id, datetime]
when wrong column type:
datetime_id: string
datetime: datetime
# Check failes when weekday is not in range 0-6
- invalid_count(weekday) = 0:
name: All weekdays are in range 0-6
valid min: 0
valid max: 6
# Check fails when customer_id is not unique
- duplicate_count(datetime_id) = 0:
name: All datetimes are unique
# Check fails when any NULL values exist in the column
- missing_count(datetime_id) = 0:
name: All datetimes have a key
# dim_product.yml
checks for dim_product:
# Check fails when product_key or english_product_name is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing: [product_id, description, price]
when wrong column type:
product_id: string
description: string
price: float64
# Check fails when customer_id is not unique
- duplicate_count(product_id) = 0:
name: All products are unique
# Check fails when any NULL values exist in the column
- missing_count(product_id) = 0:
name: All products have a key
# Check fails when any prices are negative
- min(price):
fail: when < 0
# fct_invoices.yml
checks for fct_invoices:
# Check fails when invoice_id, quantity, total is missing or
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing:
[invoice_id, product_id, customer_id, datetime_id, quantity, total]
when wrong column type:
invoice_id: string
product_id: string
customer_id: string
datetime_id: string
quantity: int
total: float64
# Check fails when NULL values in the column
- missing_count(invoice_id) = 0:
name: All invoices have a key
# Check fails when the total of any invoices is negative
- failed rows:
name: All invoices have a positive total amount
fail query: |
SELECT invoice_id, total
FROM fct_invoices
WHERE total < 0
Lets add this as a new task!
@task.external_python(python='/usr/local/airflow/soda_venv/bin/python')
def check_transform(scan_name='check_transform', checks_subpath='transform'):
from include.soda.check_function import check
return check(scan_name, checks_subpath)
Final Data Transformations and Checks for the Report
Once again we will create 3 more tables with DBT, all 3 will now have a prefix “report_”. These will be the final transformations and some additional data that will be released to the Metabase dashboard after a data quality check with SODA.
These dbt models will be stored under the following path: include/dbt/models/report:
-- report_customer_invoices.sql
SELECT
c.country,
c.iso,
COUNT(fi.invoice_id) AS total_invoices,
SUM(fi.total) AS total_revenue
FROM {{ ref('fct_invoices') }} fi
JOIN {{ ref('dim_customer') }} c ON fi.customer_id = c.customer_id
GROUP BY c.country, c.iso
ORDER BY total_revenue DESC
LIMIT 10
-- report_product_invoices.sql
SELECT
p.product_id,
p.stock_code,
p.description,
SUM(fi.quantity) AS total_quantity_sold
FROM {{ ref('fct_invoices') }} fi
JOIN {{ ref('dim_product') }} p ON fi.product_id = p.product_id
GROUP BY p.product_id, p.stock_code, p.description
ORDER BY total_quantity_sold DESC
LIMIT 10
-- report_year_invoices.sql
SELECT
dt.year,
dt.month,
COUNT(DISTINCT fi.invoice_id) AS num_invoices,
SUM(fi.total) AS total_revenue
FROM {{ ref('fct_invoices') }} fi
JOIN {{ ref('dim_datetime') }} dt ON fi.datetime_id = dt.datetime_id
GROUP BY dt.year, dt.month
ORDER BY dt.year, dt.month
Add the new task to the DAG for the final transformations.
report = DbtTaskGroup(
group_id='report',
project_config=DBT_PROJECT_CONFIG,
profile_config=DBT_CONFIG,
render_config=RenderConfig(
load_method=LoadMode.DBT_LS,
select=['path:models/report']
)
)
Store the following SODA yml files under the path: include/soda/checks/report
# report_customer_invoices.yml
checks for report_customer_invoices:
# Check fails if the country column has any missing values
- missing_count(country) = 0:
name: All customers have a country
# Check fails if the total invoices is lower or equal to 0
- min(total_invoices):
fail: when <= 0
# report_product_invoices.yml
checks for report_product_invoices:
# Check fails if the stock_code column has any missing values
- missing_count(stock_code) = 0:
name: All products have a stock code
# Check fails if the total quanity sold is lower or equal to 0
- min(total_quantity_sold):
fail: when <= 0
# report_year_invoices.yml
checks for report_year_invoices:
# Check fails if the number of invoices for a year is negative
- min(num_invoices):
fail: when < 0
Add the final task
@task.external_python(python='/usr/local/airflow/soda_venv/bin/python')
def check_report(scan_name='check_report', checks_subpath='report'):
from include.soda.check_function import check
return check(scan_name, checks_subpath)
And that is it! The data pipeline has been completed. In order to run the data pipeline in the intended order, one must use the function ‘chain’ and call all the tasks in the desired order. In essence building a dependency chain.
chain(
upload_csv_to_gcs,
create_retail_dataset,
gcs_to_raw,
check_load(),
transform,
check_transform(),
report,
check_report()
)
The Final DAG graph should look like the one attached, the graph displays all dependencies including all grouped tasks.
After entering the following yml file into your local DAG folder for the Metabase dashboard. The dashboard should appear on your local Metabase server, ready to be deployed and shared to the public. The data can be further manipulated in Metabase if needed!
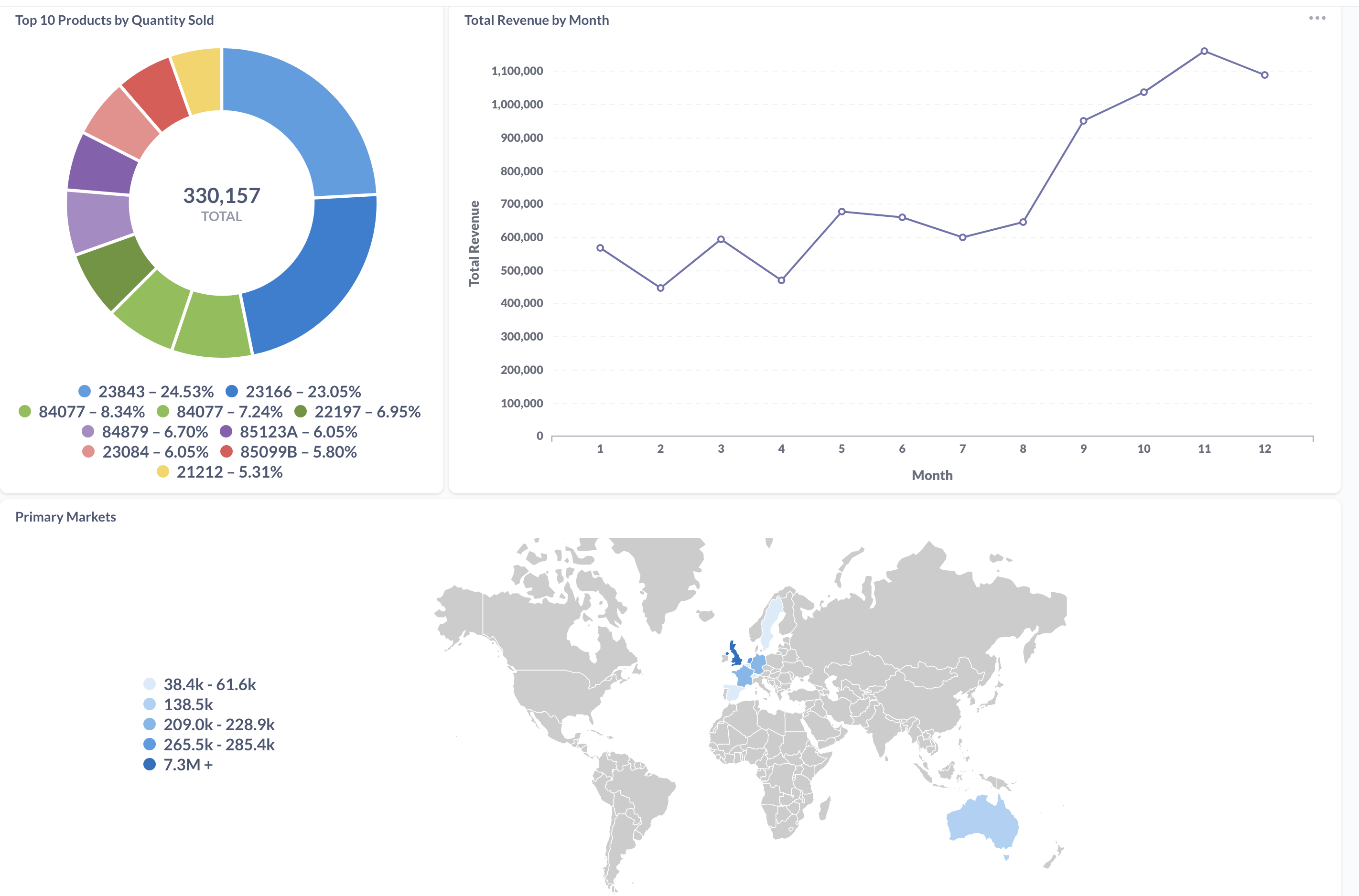
Conclusion
In conclusion, this project demonstrates the power of Apache Airflow and associated tools in orchestrating complex data pipelines. By leveraging Airflow’s DAG structure, along with tools like DBT, SODA, and Metabase, we’ve successfully ingested, transformed, and visualized retail data. The integration of these tools allows for automation, monitoring, and scalability, making it an ideal solution for end-to-end data engineering projects. Through this project, we’ve not only built a functional data pipeline but also gained insights into the seamless orchestration and management of data workflows.